Weekend projects - docs-cli-toolkit
I work daily with documentation, and my academic background is in computational linguistics. This means I like to work with text, basically.
This goes well with the new wave of AI. Tokens, PoS, corpus/corpora, terminological base, lexical combinatorics, n-grams, etc. All this was my daily life from 2012 to 2016, when I worked as a fellow at the university at Termisul and struggled daily with Python to generate a lot of XML that would serve as a basis for my terminological prediction robot. Pre-transformers era.
That said, today I am a technical writer and I am always concerned with maintaining the quality and conformity of what I write. Using only my head is not reliable - I forget a lot of things - and doing manual revisions is not always productive. Not to mention it's very tiring.
So, I decided to use my weekend to create a tool that analyzes documentation (of any size) and tries to understand how to improve it.
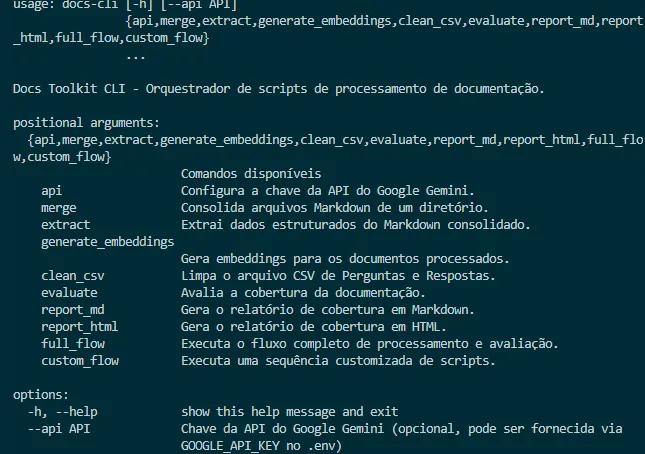
How does it work?
Basically, you first download all the documents you want to analyze, keep them in markdown format (.md). If you don't have them, convert them from html or PDF. You will also need a Google Gemini API key. You can get a free one here.
Never expose your API key on the web or commit it to GitHub. Use a
.envfile to store it or add it as an environment variable using the commanddocs-cli api <your key>.
Then you use docs-cli merge to merge all documents into a single file. Then you extract the information using the command docs-cli extract. This will give you an index in .json format that will be used to create the embeddings. To create these embeddings (explanation of what it is at the end) you will need to use the command docs-cli generate_embeddings. This process takes time, depending on how many chunks you will use and how many documents (or how large your consolidated documentation file is), it can take up to a whole day. In my program I chose chunks that mirror the markdown section. Why? Because, normally, each section has its own and complete meaning, without depending on others, which makes it easier to analyze later.
How to use?
You can use the results of your documentation (the embeddings) in 3 main ways:
- Coverage analysis: to perform a coverage analysis you will need a
.csvfile that has two columns:questionandresponse. It's good to call thedocs-cli clean_csvparameter beforehand, to make sure the file is as clean as possible. But ideally, this file should be assembled from ideal questions and answers, with the answers coming from an expert. Afterwards, rundocs-cli evaluatepassing the CSV file and the embeddings file. This script will "match" your documents according to the questions and look for them in your corpus, generating a coverage percentage for each question. Finally, you can generate an HTML report by runningdocs-cli report_htmlor a markdown report by runningdocs-cli report_md.
When using the
clean_csvparameter you will clean common noise when exporting from support and Q&A platforms, such as "menu dropdown" or "select + or -" among others. But it is possible to modify these parameters in the code.
Run an assistant: it is possible to run an assistant that will answer your questions according to what it finds in your documentation. This serves for a more detailed analysis by a human analyst who, when seeing the answers and references, can decide how adherent the answer is.
Document generator: with this knowledge base fed, cleaned and indexed, you can create a documentation draft generator. Those long guides can be generated in a short time using previous document patterns. It is more refined using your own embeddings than those of the LLM model.
Where to access?
I published the source code under the MIT license (open source) on GitHub > https://github.com/mtgr18977/docs-cli-toolkit
If you just want to install and test (and report bugs, please), you can use pip by running the command pip install docs-cli-toolkit.
The PIP page is here > https://pypi.org/project/docs-cli-toolkit/.
Anything else, you can open a PR or issue on GitHub. Or send me an email at paulo[at]paulogpd.com.br.