[Tradução Pirata] Como a IA e o vibe codding funcionam em projetos complexo e com programador experientes?
Eu não gostoi do fato de quase toda a ciência ser criada em inglês e, principalmente, de raramente termos uma tradução dessa criação. Então, como está em alta o artigo Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity que fala sobre o uso de IA por programadores experientes, onde todo mundo no LinkedIn está falando e tirando conclusões sobre, eu resolvei traduzir ele (incrivelmente, sem usar nenhuma IA, apenas colocando a minha roupa de tradutor, como eu fazia em 2013) para poder passar o link quando eu ver alguém postando o original em inglês. As imagens, infelizmente, eu vou ficar devendo a tradução.
Alguns elementos gráficos também foram deixados de lado. Ainda resta fazer a tradução dos apêndices do artigo, que trazem as informações sobre as tarefas, custos e tempo.
Medindo o Impacto da IA do Início de 2025 na Produtividade de Desenvolvedores Experientes de Open Source
Joel Becker, Nate Rush, Beth Barnes, David Rein
Model Evaluation & Threat Research (METR)
Resumo
Apesar da adoção generalizada, o impacto das ferramentas de IA no desenvolvimento de software em ambientes reais permanece pouco estudado. Conduzimos um experimento controlado randomizado (RCT) para entender como ferramentas de IA do início de 2025 afetam a produtividade de desenvolvedores experientes de open source. Dezesseis desenvolvedores com experiência moderada em IA completaram 246 tarefas em projetos maduros nos quais possuem, em média, 5 anos de experiência prévia. Cada tarefa foi aleatoriamente designada para permitir ou não o uso de ferramentas de IA. Quando permitido, os desenvolvedores usaram principalmente o Cursor Pro, um editor de código popular, e Claude 3.5/3.7 Sonnet.
Antes de iniciar as tarefas, os desenvolvedores previram que permitir IA reduziria o tempo de conclusão em 24%. Após o estudo, estimaram que a IA reduziu o tempo em 20%. Surpreendentemente, descobrimos que permitir IA aumentou o tempo de conclusão em 19%—as ferramentas de IA desaceleraram os desenvolvedores. Esse resultado contradiz também previsões de especialistas em economia (39% mais rápido) e em ML (38% mais rápido).
Para entender esse resultado, coletamos e avaliamos evidências para 20 propriedades do nosso cenário que, a priori, poderiam contribuir para o efeito observado—por exemplo, tamanho e padrões de qualidade dos projetos, ou experiência prévia dos desenvolvedores com IA. Embora não seja possível descartar totalmente a influência de artefatos experimentais, a robustez do efeito de desaceleração sugere que ele não é primariamente função do desenho experimental.
1. Introdução
O desenvolvimento de software é parte importante da economia moderna e um domínio chave para entender e prever capacidades da IA [1; 2]. Sistemas de IA de ponta demonstram capacidades impressionantes em benchmarks de software [3–9] e em experimentos que medem o impacto da IA na produtividade de desenvolvedores em tarefas sintéticas [10; 11]. No entanto, essas tarefas sacrificam realismo por escala e eficiência: são autossuficientes, exigem pouco contexto prévio e usam métricas algorítmicas que não capturam muitas capacidades importantes [12–14]. Assim, é difícil inferir o impacto prático da IA a partir desses resultados.
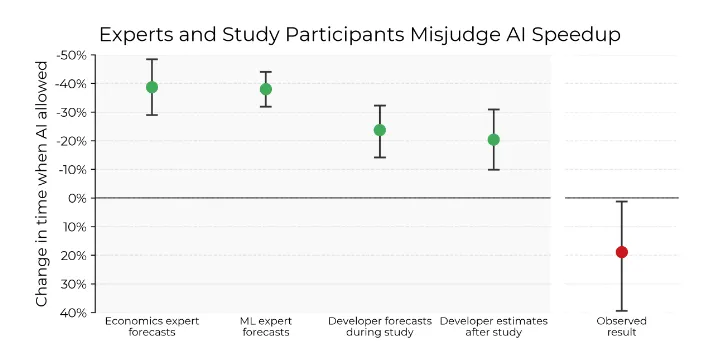
- Figura 1: Especialistas e participantes do estudo (colaboradores experientes de código aberto) superestimam substancialmente o quanto a assistência de IA acelerará os desenvolvedores - as tarefas levam 19% mais tempo quando os participantes do estudo podem usar ferramentas de IA como o Cursor Pro. Consulte o Apêndice D para obter detalhes sobre a porcentagem de aceleração e a metodologia do intervalo de confiança.*
Para reduzir essa lacuna, pode-se medir o impacto da IA em ambientes reais (experimentos de campo). Experimentos existentes medem resultados como número de linhas de código adicionadas ou tarefas concluídas [15–17]. Porém, a IA pode afetar esses resultados sem aumentar a produtividade—por exemplo, tornando o código mais verboso ou dividindo tarefas em partes menores—dificultando a interpretação.
Para medir diretamente o impacto da IA na produtividade, conduzimos um experimento randomizado com 16 desenvolvedores completando 246 tarefas (média de 2 horas cada) em repositórios open source conhecidos (média de 23.000 estrelas) nos quais contribuem regularmente. Cada tarefa foi aleatoriamente designada para permitir ou não IA, e medimos o tempo de conclusão em cada condição¹. Os desenvolvedores, com dezenas a centenas de horas de experiência prévia com LLMs², usaram ferramentas de IA de ponta (principalmente Cursor Pro com Claude 3.5/3.7 Sonnet). Gravamos as telas durante o trabalho, gerando dados ricos para análise.
Antes da randomização, os desenvolvedores previram que a IA reduziria o tempo em 24%. Após o estudo, estimaram redução de 20%. Surpreendentemente, a IA aumentou o tempo em 19%—os desenvolvedores foram mais lentos com IA. A Figura 1 mostra essa desaceleração em contraste com previsões e estimativas pós-estudo. Também coletamos previsões de especialistas em ML e economia, que superestimaram ainda mais o ganho de velocidade.
Para entender esse resultado, rotulamos manualmente 143 horas de gravações de tela (~29% do total), permitindo decompor como o tempo foi gasto com e sem IA em resolução de ~10 segundos. Também coletamos estatísticas de sistemas de controle de código, entrevistamos e aplicamos questionários aos desenvolvedores, e conduzimos análises de subconjuntos para entender melhor a desaceleração.
Com esses dados, identificamos 20 propriedades do cenário e do experimento que poderiam contribuir para a desaceleração, agrupadas em quatro categorias:
- Perda direta de produtividade: mecanismos pelos quais a IA desacelera o desenvolvimento.
- Artefato experimental: vieses do experimento que podem limitar a validade externa.
- Aumenta desempenho do desenvolvedor: atributos que favorecem o desenvolvedor em relação à IA.
- Limita desempenho da IA: atributos que prejudicam a IA em relação ao desenvolvedor.
Encontramos evidências de que 5 fatores contribuem para a desaceleração, evidências mistas/nenhuma para 9 fatores, e evidências contra 6 fatores. A Seção 3.3 apresenta esses fatores em alto nível, e o Apêndice C discute cada um em detalhe. Embora não possamos descartar totalmente artefatos experimentais, o efeito parece robusto.
Muitos fatores que contribuem para a desaceleração são específicos do cenário estudado—os resultados não implicam que sistemas atuais de IA não sejam úteis em outros contextos. Tampouco implicam que modelos futuros não possam acelerar desenvolvedores nesse cenário—isso é plausível dado o rápido progresso recente [2]. Melhorias em sistemas atuais (prompting, scaffolding, fine-tuning) também podem gerar ganhos.
Ainda assim, nossos resultados revelam um grande descompasso entre percepção e impacto real da IA na produtividade. Apesar da adoção generalizada e previsões otimistas, observamos que a IA desacelera desenvolvedores experientes nesse contexto.
1.1. Contexto
Aceleração, mas em tarefas sintéticas: A literatura sobre produtividade com IA geralmente encontra aumento de produtividade. Peng et al. [10] e Paradis et al. [11] encontram acelerações de 56% e 21% em tarefas de codificação com IA, e Weber et al. [18] encontra aumento de 65% na taxa de requisitos atendidos. Porém, usam tarefas artificiais, dificultando inferências sobre o impacto real. Por exemplo, Peng et al. [10] pede para implementar um servidor HTTP básico em JavaScript para passar testes automáticos—tarefa pouco representativa e provavelmente presente em muitos dados de treinamento de LLMs.
Aceleração, mas com métricas não fixas: Outros estudos usam tarefas reais, via experimentos naturais [16] ou randomizados [15; 17], encontrando aumentos de 14–51% em métricas de produtividade. Porém, usam métricas não fixas—linhas de código, commits, pull requests³. A IA pode aumentar esses números sem aumentar produtividade, por exemplo, tornando o código mais verboso ou dividindo PRs.
Resultados impressionantes em benchmarks: O consenso sobre o efeito da IA na produtividade é esperado, dado o desempenho aparente em benchmarks de perguntas e tarefas agenticas [19; 20].
Efeitos heterogêneos por experiência: Uma questão importante é se os ganhos de produtividade são capturados por todos os níveis de experiência. O framework de Agrawal et al. [21] trata a IA como queda no custo de predição, com consequências dependendo dos subproblemas não resolvidos. Estudos empíricos mostram que ferramentas generativas beneficiam mais trabalhadores menos experientes, comprimindo a distribuição de desempenho [22–24; 10].
Esses efeitos motivam nosso foco em desenvolvedores open source altamente qualificados, pouco estudados até então.
Resultados mistos em outros domínios: Alguns estudos medem o impacto de IA em outros contextos, como avaliação de risco CBRN, com resultados mistos [25–28]. Outros encontram aumentos substanciais de produtividade em domínios não relacionados a software [22; 23].
Entendendo o impacto econômico da IA: Por fim, alguns trabalhos tentam prever como avanços em IA podem (a) afetar o ritmo de progresso em IA (se sistemas substituírem trabalho humano em P&D), ou (b) impactar a economia. Leibowich et al. [29] entrevistam pesquisadores sobre automação total de P&D em IA, outros exploram crescimento econômico explosivo via substituição de trabalho [30–32], e a literatura econômica inclui perspectivas otimistas e céticas [33–35].

- Figura 2: Nosso projeto experimental. As tarefas (chamadas de problemas) são definidas antes da atribuição do tratamento, as gravações de tela nos permitem verificar a conformidade (e fornecem uma rica fonte de dados para análise) e as previsões de especialistas e desenvolvedores nos ajudam a medir a lacuna entre as expectativas e os resultados observados.
Nosso estudo complementa a literatura ao:
- Testar modelos de IA do início de 2025,
- Usar tarefas reais de repositórios open source, não sintéticas,
- Usar uma métrica fixa (tempo em tarefas definidas antes da randomização),
- Recrutar engenheiros experientes nos repositórios-alvo,
- Coletar dados ricos sobre uso do tempo, sugestões de IA e experiências qualitativas.
2 Metodologia
2.1 Desenvolvedores e Repositórios
Recrutamos desenvolvedores experientes de grandes repositórios open source para trabalhar em tarefas reais desses repositórios. Os desenvolvedores vêm de nossas redes profissionais e de contato com contribuidores ativos de grandes repositórios do GitHub. São engenheiros experientes (tipicamente mais de uma década de experiência) e contribuem regularmente nos repositórios usados—em média, têm 5 anos de experiência no repositório, representando 59% da vida útil do projeto, com 1.500 commits. Como incentivo, pagamos $150/hora. O Apêndice G detalha o recrutamento e incentivos.
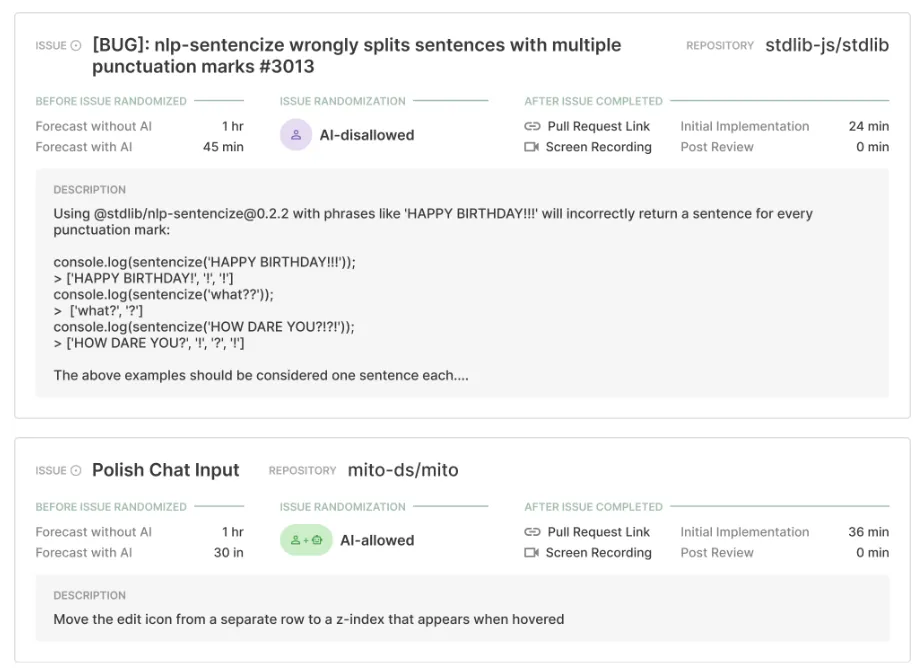
- Figura 3: Problemas reais concluídos durante o estudo nos repositórios
stdlibjs e mito.
Os repositórios são grandes e maduros. Em média, têm 23.000 estrelas, 1.100.000 linhas de código, 4.900 forks, 20.000 commits e 710 committers, com alto padrão de qualidade. Por exemplo, um guia de contribuição diz: "Ufa. Embora seja muito para lembrar [...] o objetivo é garantir que todas as contribuições atendam a um certo padrão de qualidade." A Seção G.7 detalha estatísticas dos desenvolvedores e repositórios.
Projeto Experimental
Cada desenvolvedor fornece uma lista de issues reais do seu repositório para o estudo. Issues podem ser bugs, solicitações de features ou itens de trabalho. Variam de descrições breves a análises detalhadas, com duração de minutos a horas. Dois exemplos estão na Figura 3. Muitas issues são definidas antes do estudo, outras durante⁴.
Após coletar as issues, os desenvolvedores preveem quanto tempo cada uma levaria com e sem IA. Usamos essas previsões como proxy de dificuldade e para medir o ganho esperado. As issues são então randomizadas para cada condição via sorteio⁵. Se IA é permitida, podem usar qualquer ferramenta ou nenhuma, se acharem melhor. Se não, nenhuma IA generativa pode ser usada⁶.
Os desenvolvedores trabalham nas issues na ordem que preferirem, podendo alternar entre elas. Após concluir uma issue, submetem um pull request (PR), que é revisado por outro desenvolvedor. Fazem ajustes sugeridos e mesclam o PR⁷. Como os repositórios têm alto padrão, PRs mesclados raramente têm erros. Por fim, reportam o tempo gasto antes e depois da revisão do PR.
Veja a Seção G.2 para as instruções completas dadas aos desenvolvedores.
2.2.1 Ferramentas de IA e Treinamento
Duas formas populares de usar LLMs modernos são via interfaces web (ex: chatgpt.com) e o IDE Cursor Pro (fornecemos assinatura). Cursor é um fork do VSCode com recursos extras de IA, como chat com LLM e agente que pode buscar/editar arquivos, rodar comandos, pedir detalhes ao usuário e iterar/debugar programas.
Os desenvolvedores têm experiência variada com IA: 93% já usaram ferramentas como ChatGPT, mas só 44% já usaram Cursor.
Fornecemos assinaturas do Cursor Pro e treinamento básico ao vivo, validando que sabem usar o Cursor para editar arquivos, aceitar mudanças e reverter checkpoints. Não exigimos uso do Cursor especificamente. Com IA permitida, podem usar qualquer ferramenta ou nenhuma. Veja a Seção F.2 para mais detalhes sobre acesso à IA e o Apêndice G para treinamento e onboarding.
2.2.2 Coleta de Dados
Os participantes completaram as issues como normalmente fariam, com algumas exceções: gravaram a tela (gerando dados sobre uso de IA e padrões de trabalho), usaram Cursor (às vezes diferente do ambiente usual, ex: neovim, PyCharm), e registraram detalhes do trabalho após cada issue. Em geral, relataram não terem sido significativamente afetados por essas diferenças (veja Seção 3.3 sobre possíveis efeitos do desenho experimental). Reportaram o tempo gasto antes e depois da revisão do PR.
2.3 Estimativa de Efeito
Buscamos medir a variação percentual no tempo de conclusão devido à IA, definida como:
Valor de -50% indica que issues com IA permitida levam metade do tempo das sem IA; 0% indica tempo igual; 100% indica o dobro do tempo. Para clareza, reportamos o valor absoluto de , chamando valores negativos de aceleração e positivos de desaceleração.⁸
Usamos o tempo total (pré e pós-revisão) reportado pelos desenvolvedores para estimar a variação. Algumas issues não são revisadas/mescladas—imputamos o tempo pós-revisão com a média por condição. A Seção C.3.4 mostra que os resultados são robustos ao método de imputação.
Estimamos via regressão log-linear para o tempo total, incorporando estimativas de dificuldade para reduzir ruído. Também usamos versões adaptadas para analisar subconjuntos dos dados. Veja o Apêndice D para detalhes da regressão.
2.4 Coleta de Dados Suplementares
Previsões dos desenvolvedores e estimativas pós-hoc: Antes da randomização, pedimos aos desenvolvedores que prevejam o tempo de cada issue com e sem IA. Isso fornece uma medida de dificuldade independente e permite avaliar expectativas sobre a utilidade da IA. Após o estudo, pedimos que estimem quanto a IA afetou o tempo. Isso ajuda a entender a relação entre crenças e efeitos medidos. As instruções detalhadas estão na Seção G.2.
Previsões de especialistas: Solicitamos previsões de especialistas em ML e economia para comparar com as expectativas sobre capacidades de IA [36]. Os especialistas em ML são profissionais de laboratórios de IA e acadêmicos de universidades líderes. Os de economia são principalmente acadêmicos e doutorandos. Veja a Seção E.5 para estatísticas das previsões.
Os especialistas recebem informações detalhadas sobre o estudo, repositórios e proporção de desenvolvedores com experiência em IA (Seção G.9). Eles então reportam sua previsão para nossa estimativa pontual de E[tempo sem IA]/E[tempo com IA]⁹. Para incentivar previsões precisas, oferecemos até $50 conforme a precisão.¹⁰¹¹
Dados analíticos do Cursor: Coletamos dados do painel do Cursor para os 13 desenvolvedores com assinatura Pro: modelo mais usado, número de linhas sugeridas e aceitas de código gerado por IA.
Entrevistas e questionários finais: Após o estudo, conduzimos entrevistas e questionários para avaliar onde a IA foi útil, estratégias usadas, se sentiram melhora no uso da IA e estimar o quanto foram acelerados. Detalhes completos na Seção G.5.1.
Evidências qualitativas: Durante o estudo, coletamos evidências qualitativas dos desenvolvedores para entender melhor suas experiências. Eles são instruídos a tomar notas detalhadas sobre o uso da IA, e usamos codificação indutiva para identificar padrões e temas. Resultados qualitativos na Seção 3.3. Para investigar hipóteses, às vezes fazemos perguntas direcionadas, o que pode introduzir viés.
Rotulagem fina de atividades em gravações: Para comparar como os desenvolvedores gastam o tempo com e sem IA, rotulamos manualmente 128 gravações de tela, totalizando 143 horas. Filtramos issues com trapaça, gravações quebradas (>10% do tempo) ou discrepância >20% entre tempo reportado e gravado. Restam 74 gravações (84 horas) para análise. Rotulamos se estão: codificando, testando/debugando, lendo/buscando informação, usando Git/gerenciando ambiente, interagindo com IA, esperando resposta da IA, revisando saídas da IA ou ociosos. Cada rótulo é subdividido em 27 categorias, com resolução de ~10 segundos. A Seção G.8 detalha o processo de rotulagem.
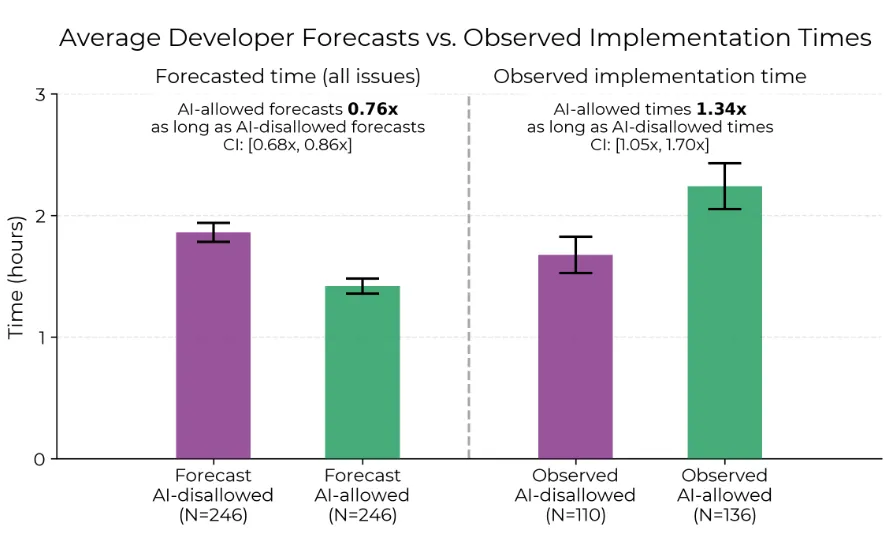
- Figura 4: Esquerda: Média bruta dos tempos de implementação previstos. À direita: Média bruta dos tempos de implementação observados. A proporção dos tempos de implementação observados fornece uma estimativa de desaceleração mais extrema do que as estimativas baseadas em regressão (Seção D.1) porque os problemas permitidos pela IA são previstos (principalmente, antes da atribuição do tratamento) pelos desenvolvedores para demorar um pouco mais, o que é corrigido pela regressão. Ambos: a Seção D.4 descreve os intervalos de confiança em torno das proporções dos tempos médios
3 Resultados
Os desenvolvedores completaram 136 issues com IA permitida e 110 sem IA. A Seção G.7 mostra a distribuição por repositório e desenvolvedor. Descobrimos que, com IA, as issues levam em média 19% mais tempo (Figura 1), e quase todos os quantis de tempo mostram maior duração com IA (Figura 5). Ou seja, os desenvolvedores são mais lentos com IA. Chamamos isso de desaceleração.
3.1 Previsões
Previsões dos desenvolvedores e estimativas pós-hoc: Antes de cada issue, os desenvolvedores preveem o tempo com e sem IA. Em média, preveem aceleração de 24%. Após o experimento, estimam aceleração de 20%—apesar de terem sido desacelerados em 19% (Figura 1). A Figura 4 mostra as médias previstas e observadas¹².
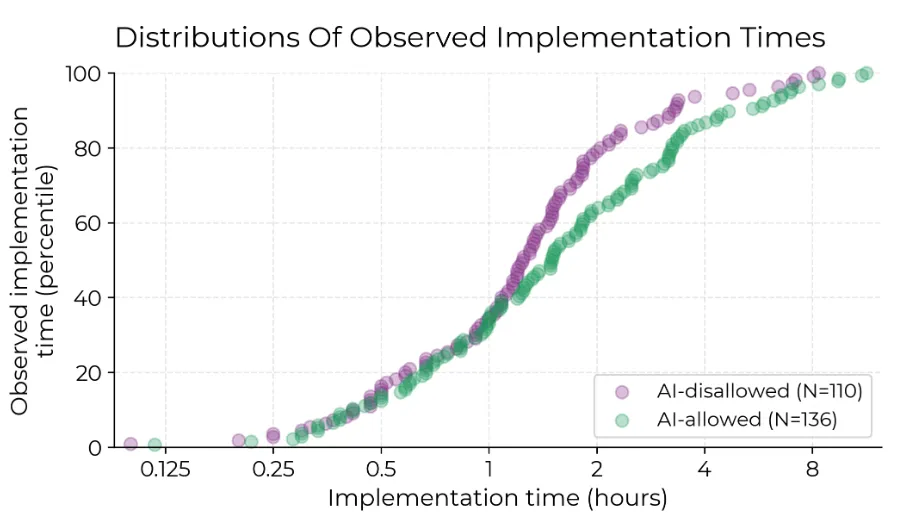
- Figura 5: Funções de distribuição cumulativa empírica dos tempos de implementação observados. A ordem dos percentis é calculada separadamente para cada grupo de tratamento.
Apesar de preverem aceleração (mas serem desacelerados), as previsões são informativas—correlação de Pearson de 0,64 para tempo previsto vs. real com IA, e 0,59 sem IA. Isso sugere que são bem calibrados quanto ao tempo relativo das issues, mas suas expectativas sobre a utilidade da IA estão invertidas.
Previsões de especialistas: Previsões de 34 especialistas em economia e 54 em ML superestimam ainda mais a aceleração, prevendo redução de 39% e 38% no tempo, respectivamente (Figura 1). Distribuições completas na Seção E.5.
3.2 Rotulagem de Atividades
Em 74 issues com gravações válidas, rotulamos manualmente as atividades dos desenvolvedores. A Figura 6 mostra a porcentagem de tempo em cada tipo de issue (com ou sem IA). Com IA, passam menos tempo codificando e buscando informação, e mais revisando saídas da IA, interagindo com IA e esperando respostas. Também passam mais tempo ociosos. A Seção E.4 mostra minutos médios e distribuições detalhadas.
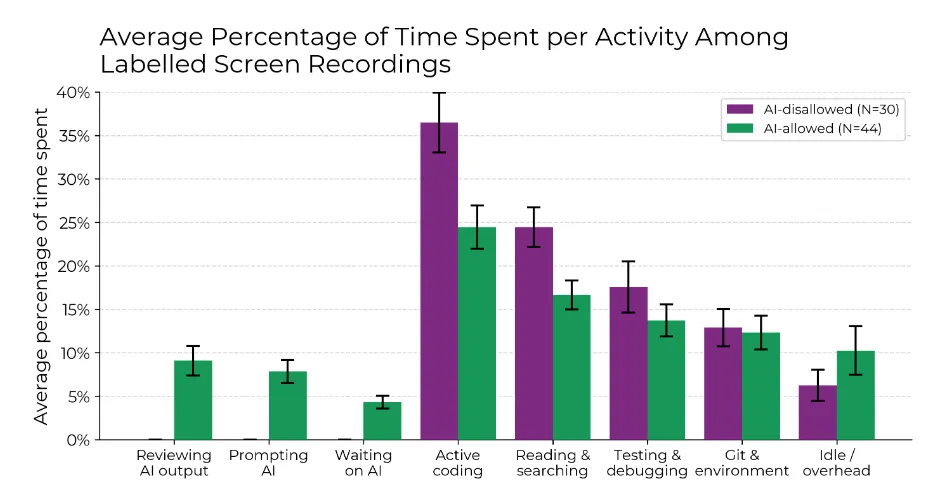
- Figura 6: no subconjunto de gravações de tela rotuladas, quando a IA é permitida, os desenvolvedores gastam menos tempo codificando ativamente e procurando/lendo informações e, em vez disso, gastam tempo solicitando a IA, aguardando e revisando os resultados da IA e ociosos. A Figura 18 mostra os minutos absolutos (médios) gastos em cada categoria, e a Figura 20 apresenta esses resultados divididos em 27 categorias de granulação fina
3.3 Análise de Fatores
Dado o resultado surpreendente, investigamos 20 fatores potenciais para a desaceleração, agrupados em:
- Perda direta de produtividade (Ý): mecanismos pelos quais a IA desacelera.
- Artefato experimental (e): vieses do experimento.
- Aumenta desempenho do desenvolvedor ( ): atributos que favorecem o desenvolvedor.
- Limita desempenho da IA (Æ): atributos que prejudicam a IA.
Com questionários, gravações, entrevistas e análises de subconjuntos, encontramos evidências qualitativas e quantitativas de que 5 fatores contribuem para a desaceleração, evidências mistas/nenhuma para 9, e evidências contra 6. Cautelamos contra supervalorizar evidências individuais, pois não temos poder estatístico para múltiplas comparações. A análise é especulativa. O Apêndice C discute cada fator na Tabela 1.
4 Discussão
Mostramos que sistemas recentes de IA desaceleram desenvolvedores experientes de open source com experiência moderada em IA, em tarefas reais de grandes repositórios. Essa desaceleração sugere que capacidades da IA no mundo real podem ser menores do que benchmarks sugerem.
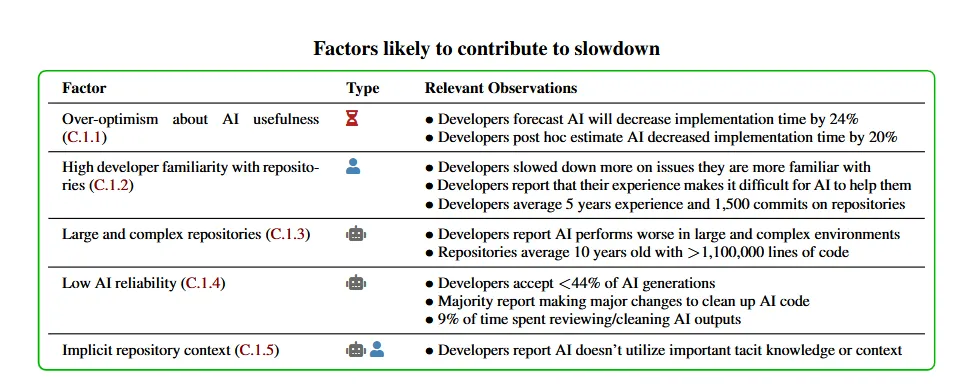
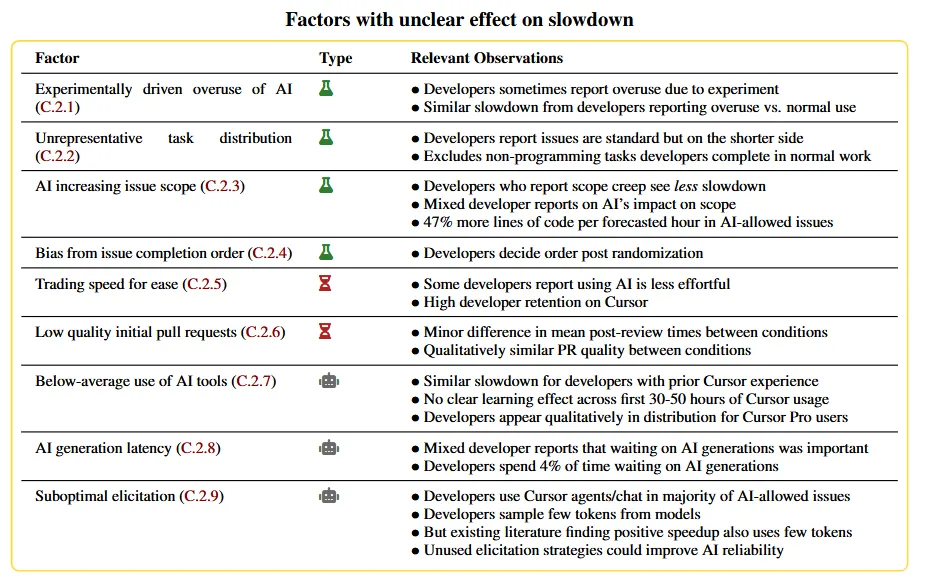
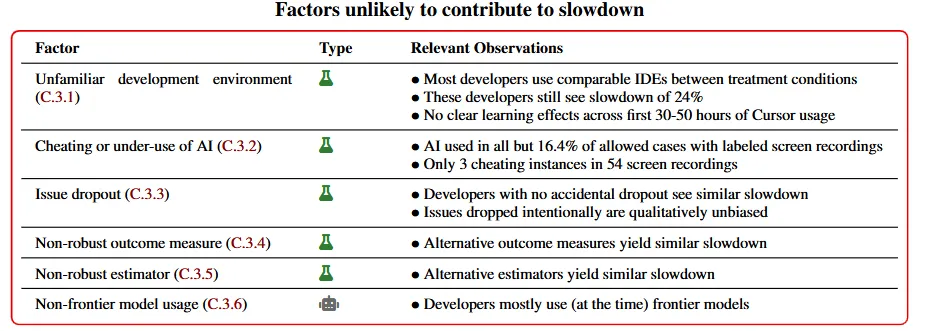
- Tabela 1: Resumo dos fatores que podem, a priori, explicar ou contribuir para a desaceleração, agrupados pelo estado das evidências a favor ou contra seu impacto no efeito da desaceleração.
Além disso, mostramos que especialistas e desenvolvedores superestimam drasticamente a utilidade da IA, mesmo após horas de uso. Isso destaca a importância de experimentos de campo com métricas robustas, em vez de confiar apenas em previsões ou questionários.
4.1 Principais Limitações
Fatores específicos do cenário: Cautelamos contra generalizações. A desaceleração observada não implica que ferramentas atuais de IA não aumentem produtividade em outros contextos—encontramos evidências de que alta familiaridade com o repositório e maturidade contribuem para a desaceleração, fatores ausentes em muitos cenários. Por exemplo, projetos pequenos ou em código desconhecido podem ver aceleração substancial.
Fatores específicos da IA: Esperamos que sistemas mais confiáveis, rápidos ou melhor elicitados (mais compute, prompting/scaffolding, fine-tuning) possam acelerar desenvolvedores nesse cenário.
Agentes podem avançar nas issues: Temos evidências preliminares (a publicar) de que agentes autônomos com Claude 3.7 Sonnet conseguem implementar a funcionalidade central de issues em vários repositórios do estudo, embora falhem em requisitos completos (documentação, lint, testes). Isso representa grande progresso em 1-2 anos, e se continuar, podemos ver aceleração significativa em breve.
5 Agradecimentos
- Agradecemos aos desenvolvedores open source que participaram deste estudo. Seu trabalho, registros e software excelentes tornaram o projeto possível. Obrigado a Aaron Diamond-Reivich, Alan Akbik, Domenic Denicola, Dens Sumesh, Jaden Fiotto-Kaufman, João Gante, Liam DeVoe, Matthew Pickering, Muhammad Haris, Philipp Burckhardt, Quentin Anthony, Ruben Bloom, Sam Derbyshire e outros desenvolvedores participantes.
- Agradecemos aos revisores pelo feedback no experimento e nos rascunhos: Adrien Ecoffet, Alexander Barry, Ali Merali, Ajeya Cotra, Andres Campero, Andrey Fradkin, Basil Halperin, Cozmin Ududec, Eli Lifland, Ernest Davis, Gregory Sun, Hjalmar Wijk, James Requeima, Jide Alaga, Josh Jacobson, Lawrence Chan, Megan Kinniment, Michael Sklar, Neev Parikh, Rif A. Saurous, Rob Miles, Ryan Greenblatt, Seraphina Nix, Sydney Von Arx, Thomas Kwa e Tom Cunningham.
- Agradecemos a Adam Hanson, Amy Ngo, Chris Canal, Jebastin Nadar, Luis Slyfield e Martin Milbradt pela ajuda na coleta de dados.
- Agradecemos Sami Jawar e Thomas Broadley pelo suporte técnico.
- Agradecemos Bhaskar Chaturvedi, Emma Abele, Kit Harris, Kris Chari, Kyle Scott, Rebecca Baron e Rae She pelo suporte operacional.
- Os autores agradecem Stephanie He pelo design gráfico.
- Agradecimentos especiais a Aron Lajko, Chris Painter, Jasmine Dhaliwal e Steve Newman pela revisão, feedback e apoio ao longo do projeto.
Referências
[1] Nestor Maslej, Loredana Fattorini, Raymond Perrault, Yolanda Gil, Vanessa Parli, Njenga Kariuki, Emily Capstick, Anka Reuel, Erik Brynjolfsson, John Etchemendy, Katrina Ligett, Terah Lyons, James Manyika, Juan Carlos Niebles, Yoav Shoham, Russell Wald, Tobi Walsh, Armin Hamrah, Lapo Santarlasci, Julia Betts Lotufo, Alexandra Rome, Andrew Shi, and Sukrut Oak. "Artificial intelligence index report 2025," 2025. URL: https://arxiv.org/abs/2504.07139.
[2] Thomas Kwa, Ben West, Joel Becker, Amy Deng, Katharyn Garcia, Max Hasin, Sami Jawhar, Megan Kinniment, Nate Rush, Sydney Von Arx, Ryan Bloom, Thomas Broadley, Haoxing Du, Brian Goodrich, Nikola Jurkovic, Luke Harold Miles, Seraphina Nix, Tao Lin, Neev Parikh, David Rein, Lucas Jun Koba Sato, Hjalmar Wijk, Daniel M. Ziegler, Elizabeth Barnes, and Lawrence Chan. "Measuring AI ability to complete long tasks," 2025. URL: https://arxiv.org/abs/2503.14499.
[3] Hjalmar Wijk, Tao Lin, Joel Becker, Sami Jawhar, Neev Parikh, Thomas Broadley, Lawrence Chan, Michael Chen, Josh Clymer, Jai Dhyani, Elena Ericheva, Katharyn Garcia, Brian Goodrich, Nikola Jurkovic, Holden Karnofsky, Megan Kinniment, Aron Lajko, Seraphina Nix, Lucas Sato, William Saunders, Maksym Taran, Ben West, and Elizabeth Barnes. "Re-bench: Evaluating frontier AI R&D capabilities of language model agents against human experts," 2025. URL: https://arxiv.org/abs/2411.15114.
[4] Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng, and Aleksander Madry. "MLE-bench: Evaluating machine learning agents on machine learning engineering," 2025. URL: https://arxiv.org/abs/2410.07095.
[5] Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. "PaperBench: Evaluating AI's ability to replicate AI research," 2025. URL: https://arxiv.org/abs/2504.01848.
[6] Shanghaoran Quan, Jiaxi Yang, Bowen Yu, Bo Zheng, Dayiheng Liu, An Yang, Xuancheng Ren, Bofei Gao, Yibo Miao, Yunlong Feng, Zekun Wang, Jian Yang, Zeyu Cui, Yang Fan, Yichang Zhang, Binyuan Hui, and Junyang Lin. "CodeElo: Benchmarking competition-level code generation of LLMs with human-comparable Elo ratings," 2025. URL: https://arxiv.org/abs/2501.01257.
[7] Samuel Miserendino, Michele Wang, Tejal Patwardhan, and Johannes Heidecke. "SWE-lancer: Can frontier LLMs earn $1 million from real-world freelance software engineering?," 2025. URL: https://arxiv.org/abs/2502.12115.
[8] David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. "GPQA: A graduate-level Google-proof Q&A benchmark," 2023. URL: https://arxiv.org/abs/2311.12022.
[9] David Rein, Joel Becker, Amy Deng, Seraphina Nix, Chris Canal, Daniel O'Connel, Pip Arnott, Ryan Bloom, Thomas Broadley, Katharyn Garcia, Brian Goodrich, Max Hasin, Sami Jawhar, Megan Kinniment, Thomas Kwa, Aron Lajko, Nate Rush, Lucas Jun Koba Sato, Sydney Von Arx, Ben West, Lawrence Chan, and Elizabeth Barnes. "HCAST: Human-calibrated autonomy software tasks," 2025. URL: https://arxiv.org/abs/2503.17354.
[10] Sida Peng, Eirini Kalliamvakou, Peter Cihon, and Mert Demirer. "The impact of AI on developer productivity: Evidence from GitHub Copilot," 2023. URL: https://arxiv.org/abs/2302.06590.
[11] Elise Paradis, Kate Grey, Quinn Madison, Daye Nam, Andrew Macvean, Vahid Meimand, Nan Zhang, Ben Ferrari-Church, and Satish Chandra. "How much does AI impact development speed? An enterprise-based randomized controlled trial," 2024. URL: https://arxiv.org/abs/2410.12944.
[12] Inioluwa Deborah Raji, Emily M. Bender, Amandalynne Paullada, Emily Denton, and Alex Hanna. "AI and the everything in the whole wide world benchmark," 2021. URL: https://arxiv.org/abs/2111.15366.
[13] Stella Biderman, Hailey Schoelkopf, Lintang Sutawika, Leo Gao, Jonathan Tow, Baber Abbasi, Alham Fikri Aji, Pawan Sasanka Ammanamanchi, Sidney Black, Jordan Clive, Anthony DiPofi, Julen Etxaniz, Benjamin Fattori, Jessica Zosa Forde, Charles Foster, Jeffrey Hsu, Mimansa Jaiswal, Wilson Y. Lee, Haonan Li, Charles Lovering, Niklas Muennighoff, Ellie Pavlick, Jason Phang, Aviya Skowron, Samson Tan, Xiangru Tang, Kevin A. Wang, Genta Indra Winata, François Yvon, and Andy Zou. "Lessons from the trenches on reproducible evaluation of language models," 2024. URL: https://arxiv.org/abs/2405.14782.
[14] Ernest Davis. "Benchmarks for automated commonsense reasoning: A survey," 2023. URL: https://arxiv.org/abs/2302.04752.
[15] Leonardo Gambacorta, Han Qiu, Shuo Shan, and Daniel M Rees. "Generative AI and labour productivity: a field experiment on coding," Volume 1208. Bank for International Settlements, Monetary and Economic Department, 2024.
[16] Doron Yeverechyahu, Raveesh Mayya, and Gal Oestreicher-Singer. "The impact of large language models on open-source innovation: Evidence from GitHub Copilot," 2025. URL: https://ssrn.com/abstract=4684662.
[17] Zheyuan Cui, Mert Demirer, Sonia Jaffe, Leon Musolff, Sida Peng, and Tobias Salz. "The effects of generative AI on high-skilled work: Evidence from three field experiments with software developers," June 2025. URL: https://ssrn.com/abstract=4945566.
[18] Thomas Weber, Maximilian Brandmaier, Albrecht Schmidt, and Sven Mayer. "Significant productivity gains through programming with large language models." Proc. ACM Hum.-Comput. Interact., 8(EICS), June 2024. DOI: 10.1145/3661145. URL: https://doi.org/10.1145/3661145.
[19] OpenAI. "OpenAI o3 and o4-mini System Card." https://cdn.openai.com/pdf/2221c875-02dc-4789-800b-e7758f3722c1/o3-and-o4-mini-system-card.pdf, 2025. [Accessed 23-06-2025].
[20] Anthropic. "Anthropic Claude 4 System Card." https://www-cdn.anthropic.com/6be99a52cb68eb70eb9572b4cafad13df32ed995.pdf, 2025. [Accessed 23-06-2025].
[21] Ajay Agrawal, Joshua S. Gans, and Avi Goldfarb. "Artificial intelligence: The ambiguous labor market impact of automating prediction." Journal of Economic Perspectives, 33(2):31–50, May 2019. DOI: 10.1257/jep.33.2.31. URL: https://www.aeaweb.org/articles?id=10.1257/jep.33.2.31.
[22] Erik Brynjolfsson, Danielle Li, and Lindsey Raymond. "Generative AI at work." The Quarterly Journal of Economics, 140(2):889–942, 02 2025. ISSN 0033-5533. DOI: 10.1093/qje/qjae044. URL: https://doi.org/10.1093/qje/qjae044.
[23] Shakked Noy and Whitney Zhang. "Experimental evidence on the productivity effects of generative artificial intelligence." Science, 381(6654):187–192, 2023. DOI: 10.1126/science.adh2586. URL: https://www.science.org/doi/abs/10.1126/science.adh2586.
[24] Jonathan H. Choi and Daniel Schwarcz. "AI assistance in legal analysis: An empirical study." Journal of Legal Education, 73(2), 2025. URL: https://jle.aals.org/home/vol73/iss2/5/.
[25] Anthropic. "Responsible scaling policy evaluations report – Claude 3 Opus." Technical report, Anthropic, 2024. URL: https://cdn.sanity.io/files/4zrzovbb/website/210523b8e11b09c704c5e185fd362fe9e648d457.pdf. [Accessed June 2025].
[26] C. Mouton, Caleb Lucas, and Ella Guest. "The operational risks of AI in large-scale biological attacks." Research report, RAND Corporation, Santa Monica, 2024. URL: https://www.rand.org/content/dam/rand/pubs/research_reports/RRA2900/RRA2977-2/RAND_RRA2977-2.pdf.
[27] Aaron Grattafiori et al. "The Llama 3 herd of models," 2024. URL: https://arxiv.org/abs/2407.21783.
[28] Tejal Patwardhan, Kevin Liu, Todor Markov, Neil Chowdhury, Dillon Leet, Natalie Cone, Caitlin Maltbie, Joost Huizinga, Carroll Wainwright, Shawn (Froggi) Jackson, Steven Adler, Rocco Casagrande, and Aleksander Madry. "Building an early warning system for LLM-aided biological threat creation." https://openai.com/index/building-an-early-warning-system-for-llm-aided-biological-threat-creation/, January 2024. [Accessed: 2025-06-25].
[29] Jared Leibowich, Nikola Jurkovic, and Tom Davidson. "Could advanced AI accelerate the pace of AI progress? Interviews with AI researchers," 2024. URL: https://ssrn.com/abstract=5115692.
[30] Ege Erdil and Tamay Besiroglu. "Explosive growth from AI automation: A review of the arguments," 2024. URL: https://arxiv.org/abs/2309.11690.
[31] Ege Erdil, Andrei Potlogea, Tamay Besiroglu, Edu Roldan, Anson Ho, Jaime Sevilla, Matthew Barnett, Matej Vrzla, and Robert Sandler. "GATE: An integrated assessment model for AI automation," 2025. URL: https://arxiv.org/abs/2503.04941.
[32] Tom Davidson. "What a compute-centric framework says about takeoff speeds." https://www.openphilanthropy.org/research/what-a-compute-centric-framework-says-about-takeoff-speeds/, June 2023. Open Philanthropy. [Accessed: 2025-06-25].
[33] Daron Acemoglu. "The simple macroeconomics of AI." Economic Policy, 40(121):13–58, 08 2024. ISSN 0266-4658. DOI: 10.1093/epolic/eiae042. URL: https://doi.org/10.1093/epolic/eiae042.
[34] Ajay Agrawal, Joshua Gans, and Avi Goldfarb. "Economic policy for artificial intelligence." Innovation Policy and the Economy, 19:139–159, 2019. DOI: 10.1086/699935. URL: https://doi.org/10.1086/699935.
[35] Jason Furman and Robert Seamans. "AI and the Economy," pages 161–191. University of Chicago Press, May 2018. DOI: 10.1086/699936. URL: http://www.nber.org/chapters/c14099.
[36] Stefano DellaVigna, Nicholas Otis, and Eva Vivalt. "Forecasting the results of experiments: Piloting an elicitation strategy." AEA Papers and Proceedings, 110:75–79, May 2020. DOI: 10.1257/pandp.20201080. URL: https://www.aeaweb.org/articles?id=10.1257/pandp.20201080.
[37] Tilmann Gneiting and Adrian E Raftery. "Strictly proper scoring rules, prediction, and estimation." Journal of the American Statistical Association, 102(477):359–378, 2007. DOI: 10.1198/016214506000001437. URL: https://doi.org/10.1198/016214506000001437.
[38] Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. "SWE-bench: Can language models resolve real-world GitHub issues?" In The Twelfth International Conference on Learning Representations, 2024. URL: https://openreview.net/forum?id=VTF8yNQM66.
[39] Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. "Lost in the middle: How language models use long contexts," 2023. URL: https://arxiv.org/abs/2307.03172.
[40] Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. "Scaling LLM test-time compute optimally can be more effective than scaling model parameters," 2024. URL: https://arxiv.org/abs/2408.03314.
[41] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. "Self-consistency improves chain of thought reasoning in language models," 2023. URL: https://arxiv.org/abs/2203.11171.
[42] Stack Overflow. "2024 developer survey: Technology - integrated development environment," 2024. URL: https://survey.stackoverflow.co/2024/technology#1-integrated-development-environment. [Accessed: June 26, 2025].