Como prever termos em uma busca?
Ontem um amigo mandou um texto do Tumblr (SIM!) sobre como o ChatGPT opera. Ou seja, como o ChatGPT entende o que vem depois e depois e depois. Como ele cria a "cadeia de pensamento" (não estou falando do chain of thought dos novos assistentes) que leva uma pergunta -> resposta.
De forma resumida, o ChatGPT, e qualquer sistema de LLM ou de previsão terminológica, trabalha com reforço de aprendizagem e reconhecimento de padrões. Algo que nós, humanos, somos muito bons, diga-se de passagem. O texto, em EN, fala sobre isso. Sobre um trabalhador imaginário que fica adivinhando caracteres chineses em uma tela. O que ele faz é receber um sinal de erro quando ele erra o caracter subsequente e um sinal de acerto quando ele acerta. Uma abordagem skuneriana, que funciona com pessoas e com máquinas.
É mais ou menos o que pensamos sobre os problemas e soluções das previsões da época do Google (que morreu como buscador e renasceu como empresa de IA). Eu precisei desenhar um diagrama pra tentar explicar melhor, com palavras é sempre ruim (ou pior).
Primeiro vamos entender como o Google previa as n-gramas de um texto, o que é de, forma extrapolada, o mesmo principio sobre o qual operam os assistentes:
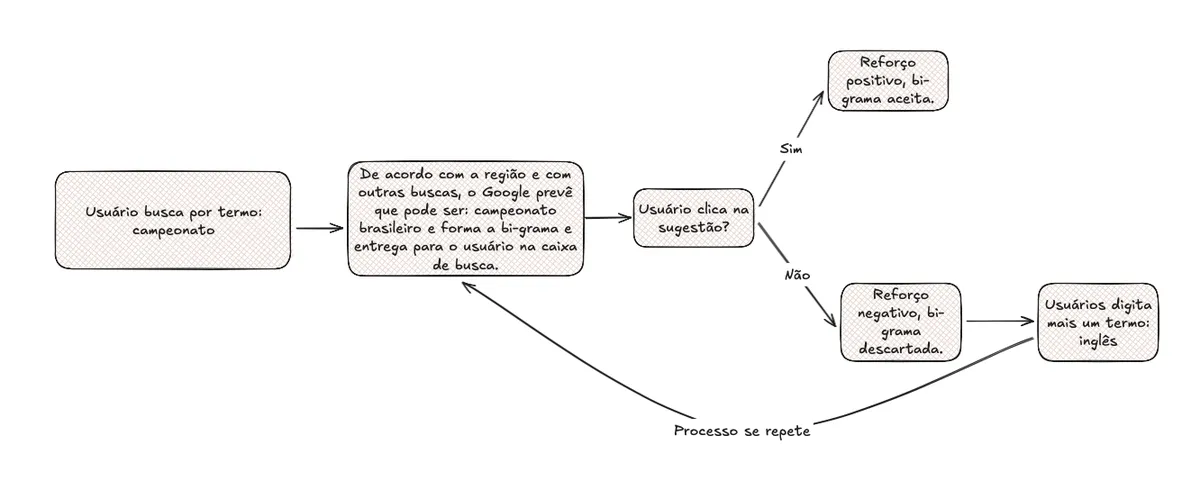
E depois como funcionam as n-gramas:
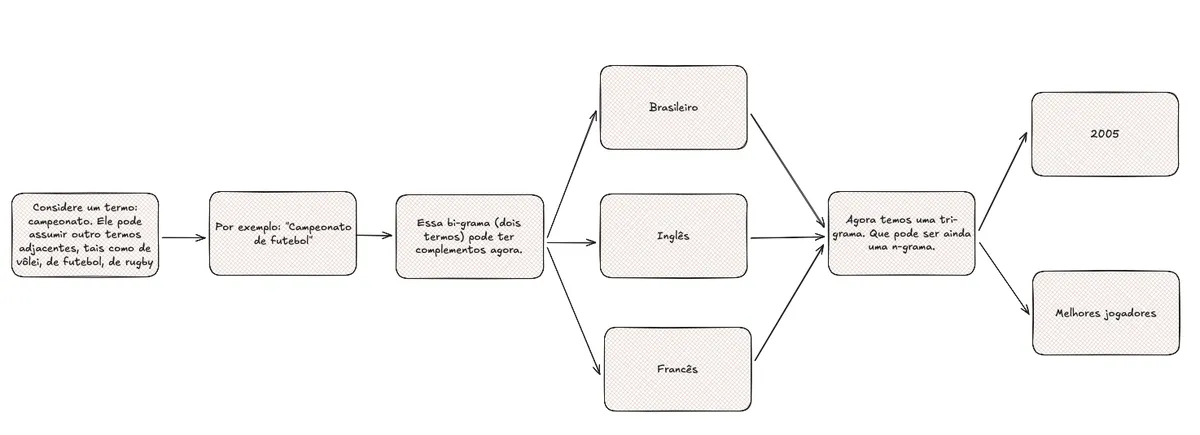
De forma resumida é isso, e por isso que os assistentes precisam de todos os dados possíveis. ELes precisam montar um corpus com os textos e aplicar diversos algoritmos de transformação, tokenização e recuperação da informação para, quando você perguntar o que é bom para queimadura de pele, ele conseguir entender o padrão de "símbolos" que você passou e buscar na base de conhecimento dele (contruída por décadas de internet aberta) o que mais se encaixa naquele padrão.
É basicamente isso.